
概要
さまざまな記述統計量、グラフ表示、統計方法を提供します。
構文
PROC UNIVARIATE <option(s)>;
BY variables;
CDFPLOT <variables> < / options>;
CLASS variable-1 <(v-options)> <variable-2 <(v-options)>>
</ KEYLEVEL = value1 | (value1 value2)>);
FREQ variable;
HISTOGRAM <variables> < / options>;
ID variables;
INSET keyword-list </ options>;
OUTPUT <OUT=SAS-data-set>
<keyword1=names ...keywordk=names>
<percentile-options>;
PPPLOT <variables> < / options>;
PROBPLOT <variables> < / options>;
QQPLOT <variables> < / options>;
VAR variables;
WEIGHT variable;
RUN;
ステートメントの説明
| ステートメント | 必須 | 解説 |
| BY | BYグループごとの独立した分析を取得できます。 | |
| CDFPLOT | 変数の観測された累積分布関数(CDF)をプロットします。 | |
| CLASS | データを各分類水準にグループ化するときに使用する変数を、1つまたは2つ指定します。 | |
| FREQ | オブザベーションの度数を表します(FREQステートメントは数値変数を指定します)。 | |
| HISTOGRAM | ヒストグラムを作成します。 WEIGHTステートメントをHISTOGRAMステートメントと併用することはできません。 | |
| ID | 極値オブザベーションのテーブルに含める変数を1つ以上指定します。 IDOUTオプションを指定すると、OUTPUTステートメントで作成される出力データセットにID変数を含めることができます。 | |
| INSET | CDFPLOT、HISTOGRAM、PPPLOT、PROBPLOT、QQPLOTのいずれかのステートメントで作成されたグラフ内に直接、インセットと呼ばれる要約統計量のボックスまたはテーブルを配置します。 | |
| OUTPUT | 統計量とBY変数を出力データセットに保存します。 | |
| PPPLOT | P-Pプロット(パーセントプロット)を作成します。 | |
| PROBPLOT | 確率プロットを作成します。 | |
| QQPLOT | Q-Qプロットを作成し、並べ替えられた変数値を指定した理論分布の分位点と比較します。 ※Q-Qプロット(quantile-quantile plot):2つの確率分布を比較する方法 ※quantile:分位数 | |
| VAR | 分析変数とその結果の出力順序を指定します。省略すると、他のステートメント内でリストされていないすべての数値変数が分析されます。 | |
| WEIGHT | 統計量計算における分析変数の数値の重みを指定します。 |
PROC UNIVARIATEステートメントのオプション(抜粋)
| オプション | 要約 |
| ALL | FREQ、MODES、NEXTRVAL= 5、PLOTS、CIBASICオプションが生成するすべての統計量とテーブルを要求します。 |
| ALPHA=α | 有意水準α(100(1 – α) % 信頼区間) を指定します。 ただし、0 <= α <= 1 デフォルト値は 0.05 であり、これは 95% の信頼区間を生成します。 |
| DATA=SAS-data-set | 入力SASデータセットを指定します。DATA=オプションを省略すると、最後に作成された SASデータセットが使用されます。 |
| NOPRINT | PROC UNIVARIATEステートメントで作成される記述統計量のテーブルをすべて抑制します。NOPRINTを指定しても、HISTOGRAMステートメントで作成されるテーブルは抑制されません。HISTOGRAMステートメントのテーブルの作成を抑制するには、HISTOGRAMステートメントのNOPRINTオプションを使用します。 |
| OUTTABLE=SAS-data-set | 分析変数ごとに1つのオブザベーションの表形式にまとめられた、単変量統計量を含む出力データセットを作成します。 |
OUTPUTステートメントのオプション(抜粋)
| オプション | 要約 |
| OUT=SAS-data-set | 出力データセットを指定します。 |
| keyword1=names | 出力データセットに含める統計量を選択し、その統計量を含む新しい変数に名前を付けることができます。 |
keyword1=namesオプションで利用できるキーワード(記述統計)
| キーワード | 要約 |
| CSS | 修正済み平方和 |
| CV | 変動係数 |
| GEOMEAN | 幾何平均 |
| KURTOSIS | KURT | 尖度 |
| MAX | 最大値 |
| MEAN | 標本平均 |
| MIN | 最小値 |
| MODE | 最も度数の高い値 |
| N | 標本サイズ |
| NMISS | 欠損値の数 |
| NOBS | オブザベーションの数 |
| RANGE | 範囲 |
| SKEWNESS | SKEW | 歪度 |
| STD | STDDEV | 標準偏差 |
| STDMEAN | STDERR | 平均の標準誤差 |
| SUM | オブザベーションの合計 |
| SUMWGT | 重みの合計 |
| USS | 無修正平方和 |
| VAR | 分散 |
keyword1=namesオプションで利用できるキーワード(分位点統計)
| キーワード | 要約 |
| P1 | 1番目のパーセント点 |
| P5 | 5番目のパーセント点 |
| P10 | 10番目のパーセント点 |
| Q1 | P25 | 下位四分位点(25番目のパーセント点) |
| MEDIAN | Q2 | P50 | 中央値(50番目のパーセント点) |
| Q3 | P75 | 上位四分位点(75番目のパーセント点) |
| P90 | 90番目のパーセント点 |
| P95 | 95番目のパーセント点 |
| P99 | 99番目のパーセント点 |
| QRANGE | 四分位範囲(Q3‒Q1) |
keyword1=namesオプションで利用できるキーワード(ロバスト統計量)
| キーワード | 要約 |
| GINI | Giniの平均差 |
| MAD | 中央絶対偏差 |
| QN | Qn 、MADの代替 |
| SN | Sn 、MADの代替 |
| STD_GINI | Giniの標準偏差 |
| STD_MAD | MADの標準偏差 |
| STD_QN | Qn 標準偏差 |
| STD_QRANGE | 四分位範囲標準偏差 |
| STD_SN | Sn 標準偏差 |
keyword1=namesオプションで利用できるキーワード(仮説検定)
| キーワード | 要約 |
| MSIGN | 符号統計量 |
| NORMALTEST | 正規性の検定 |
| SIGNRANK | 符号付き順位統計量 |
| PROBM | 符号検定でのより大きな絶対値の確率 |
| PROBN | 正規性の検定の確率値 |
| PROBS | 符号付き順位検定の確率値 |
| PROBT | スチューデントのt検定の確率値 |
| T | スチューデントのt検定の統計量 |
例1:ステートメント無しで実行してみる
proc univariate data = sashelp.class;
run;利用したテストデータ(sashelp.class)の身長、体重の単位はアメリカ仕様(ヤード、ポンド)となっているようです。
ステートメントを記述しなければ読み込んだデータセット内のすべての数値変数についての統計量や分位点などを出力します。
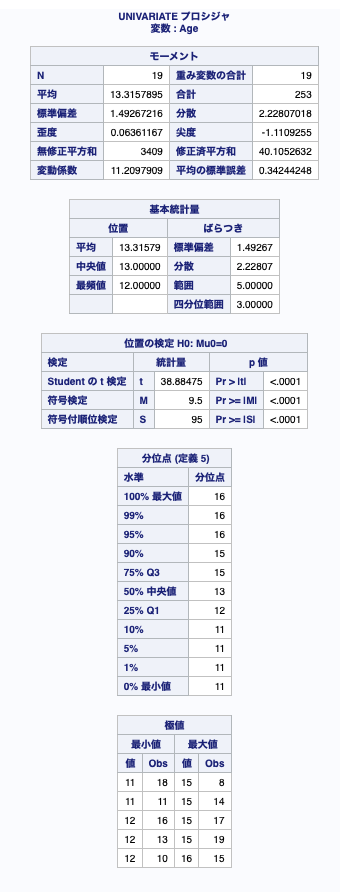
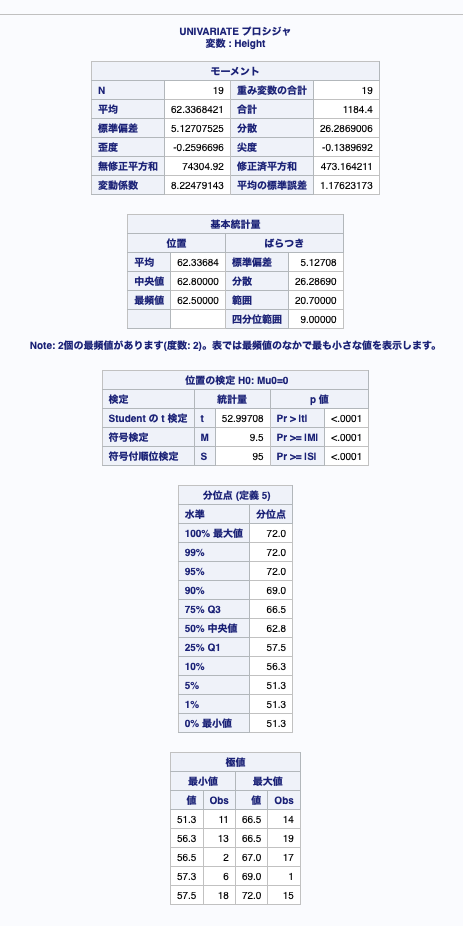
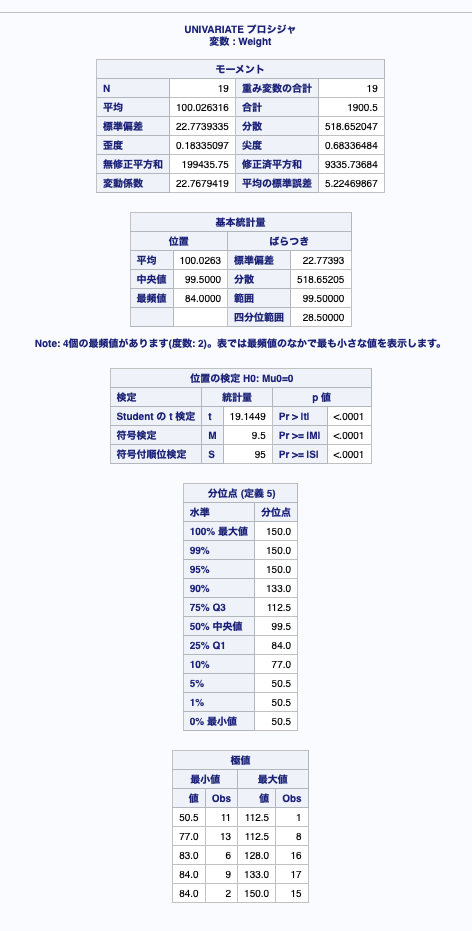
例2:outputステートメントで出力データセットを指定し、統計量を出力
proc univariate data = sashelp.class noprint;
var height;
output out = out_ds1
mean = heikin
std = h_hensa
max = saidai
min = saisyo;
run;
例3:複数の変数の統計量を出力
proc univariate data = sashelp.class noprint;
var age height weight;
output out = out_ds2
mean = heikin_1 heikin_2 heikin_3
std = h_hensa_1 h_hensa_2 h_hensa_3
max = saidai_1 saidai_2 saidai_3
min = saisyo_1 saisyo_2 saisyo_3;
run;このケースはよく使います。
(列数が多いので便宜的に行を分けて表示しています。)


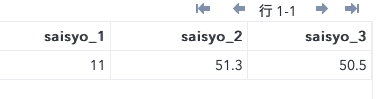
例4:すべての統計量を出力
proc univariateステートメントのouttableオプションを利用するとすべての数値変数のすべての統計量を出力します。
proc univariate data = sashelp.class outtable = out_ds3 noprint;
run;(列数が多いので便宜的に行を分けて表示しています。)









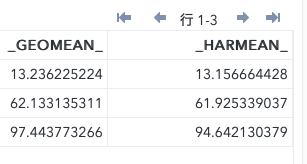
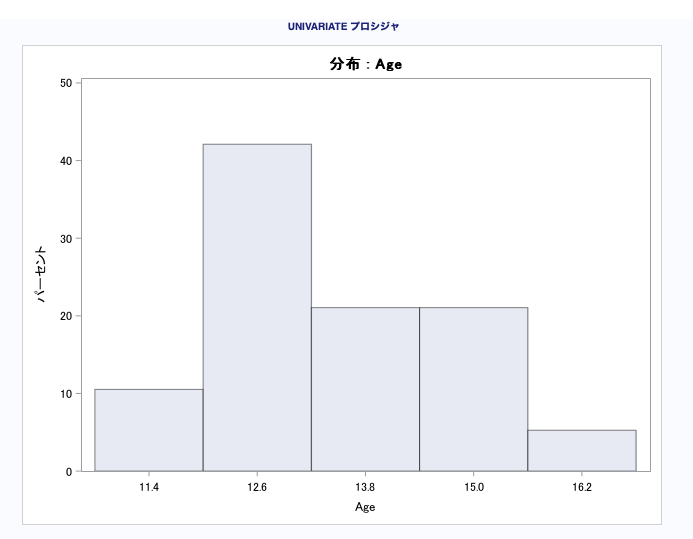
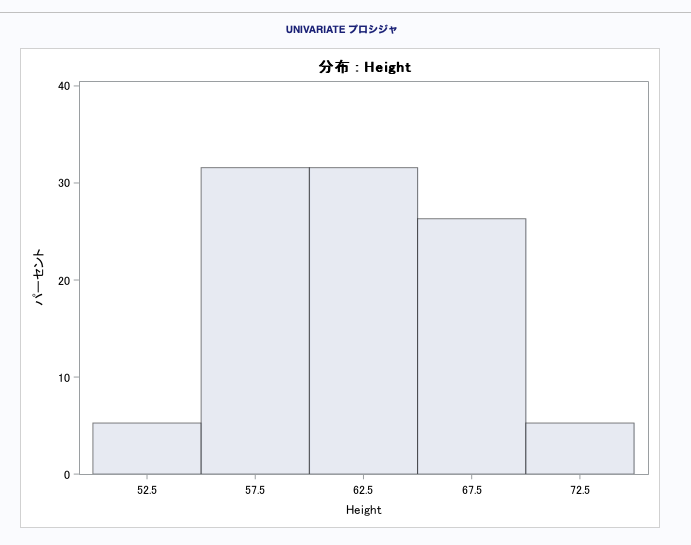
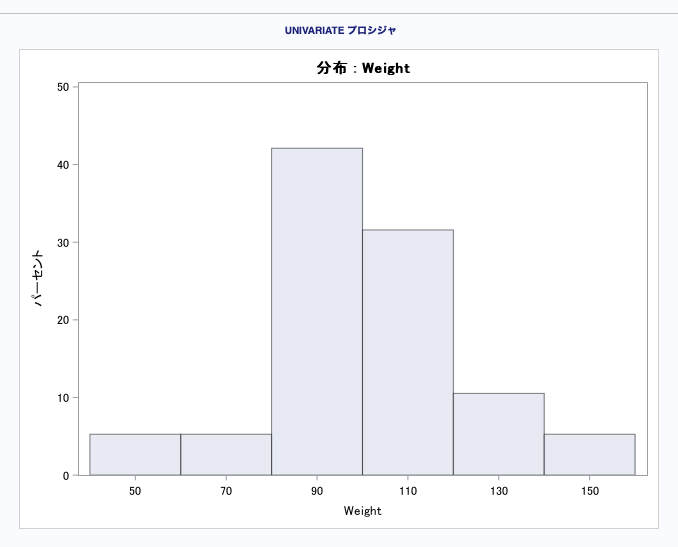
例5:ヒストグラムを描く
proc univariate data = sashelp.class noprint;
histogram;
run;histgramステートメントは、1次オプション2次オプションがあり、かなり量がありここでは書ききれないので詳細はマニュアルを参照してください。

コメント