
概要:記述統計量を計算します。
構文
PROC MEANS <option(s)> <statistic-keyword(s)>;
BY <DESCENDING> variable-1
<<DESCENDING> variable-2 ...>
<NOTSORTED>;
CLASS variable(s)</ options(s)>;
FREQ variable;
ID variable(s);
OUTPUT <OUT=SAS-data-set>
<output-statistic-specification(s)>
<id-group-specification(s)>
<maximum-id-specification(s)>
<minimum-id-specification(s)>
</ option(s)>;
TYPES request(s);
VAR variable(s)</ WEIGHT=weight-variable>;
WAYS list;
WEIGHT variable;
RUN;
ステートメントの説明
| ステートメント | 必須 | 解説 |
| BY | BYグループごとに別の統計量を計算します。 | |
| CLASS | 値が分析対象のサブグループを定義する変数を識別します。 | |
| FREQ | 値が各オブザベーションの度数を表す変数を識別します。 | |
| ID | 追加のID変数を出力データセットに含めます。 | |
| OUTPUT | 指定されている統計量とID変数を含む出力データを作成します。 | |
| TYPES | データの分割に使用する分類変数の特定の組み合わせを識別します。 | |
| VAR | 分析変数と結果での順序を識別します。 | |
| WAYS | 分類変数の一意の組み合わせを作成するための方法の数を指定します。 | |
| WEIGHT | 値が統計量計算で各オブザベーションを重みをつける変数を識別します。 |
PROC MEANSステートメントのオプション
| オプション | 要約 |
| DATA=SAS-data-set | 入力データセットを指定します。 |
| NOTRAP | 浮動小数点例外の復旧を無効化します。 |
| PCTLDEF= | 分位点の計算に使用される数学的定義を指定します。 |
| SUMSIZE=value | 分類変数によるデータ要約に使用するメモリ量を指定します。 |
| THREADS | NOTHREADS | SAS システムオプション THREADS | NOTHREADS を指定します。 |
Control the classification levels
| オプション | 要約 |
| CLASSDATA=SAS-data-set | 分析する分類変数の組み合わせを含む2次データセットを指定します。 |
| COMPLETETYPES | 分類変数値の可能な組み合わせをすべて作成します。 |
| EXCLUSIVE | CLASSDATA=データセットにない分類変数値の組み合わせをすべて分析から除外します。 |
| MISSING | 欠損値を有効値として使用し、分類変数の組み合わせを作成します。 |
Control the output
| オプション | 要約 |
| FW=field-width | 統計量のフィールド幅を指定します。 |
| MAXDEC=number | 統計量に対し小数点以下の桁数を指定します。 |
| NONOBS | 分類変数の一意の各組み合わせに対するオブザベーション合計数のレポ ートを行いません。 |
| NOPRINT | 表示されているすべての出力を非表示にします。 |
| ORDER=DATA | FORMATTED | FREQ | UNFORMATTED | 分類変数の値を指定されている順序に従って並べ替えます。 |
| PRINT | NOPRINT | 出力を表示します(しません)。 |
| PRINTALLTYPES | 分類変数の要求されたすべての組み合わせに対する分析を表示します。 |
| PRINTIDVARS | ID変数の値を表示します。 |
| STACKODSOUTPUT | ODS出力オブジェクトを生成します。 |
Control the output data set
| オプション | 要約 |
| CHARTYPE | _TYPE_変数に文字値が含まれるように指定します。 |
| DESCENDTYPES | _TYPE_値の降順で出力データセットを並べ替えます。 |
| IDMIN | ID変数を最小値に基づいて選択します。 |
| NWAY | 出力統計量をTYPEの値が最高のオブザベーションに制限します。 |
Control the statistical analysis
| オプション | 要約 |
| ALPHA=value | 信頼限界に対する信頼水準を指定します。 |
| EXCLNPWGTS | 非正の重みが付いたオブザベーションを分析から除外します。 |
| QMARKERS=number | P2分位点推定方法に使用するサンプルサイズを指定します。 |
| QMETHOD=OS|P2 | 分位点推定方法を指定します。 |
| QNTLDEF=1 | 2 | 3 | 4 | 5 | 分位点の計算に使用される数学的定義を指定します。 |
| statistic-keyword(s) | 統計量を選択します。 |
| VARDEF=divisor | 分散の計算のための分母を指定します。 |
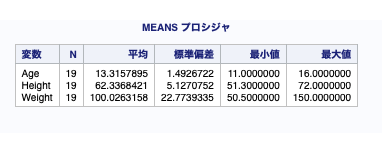
例1
proc means data = sashelp.class; run;
例2
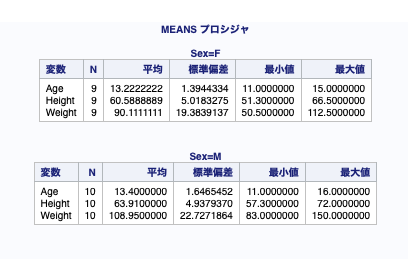
性別ごとの年齢、身長、体重について出す。
データセットに出力する。
事前にソートします。
proc sort data = sashelp.class out = class; by sex; run;
proc means data = class; by sex; var age height weight; output out = class_test; run;
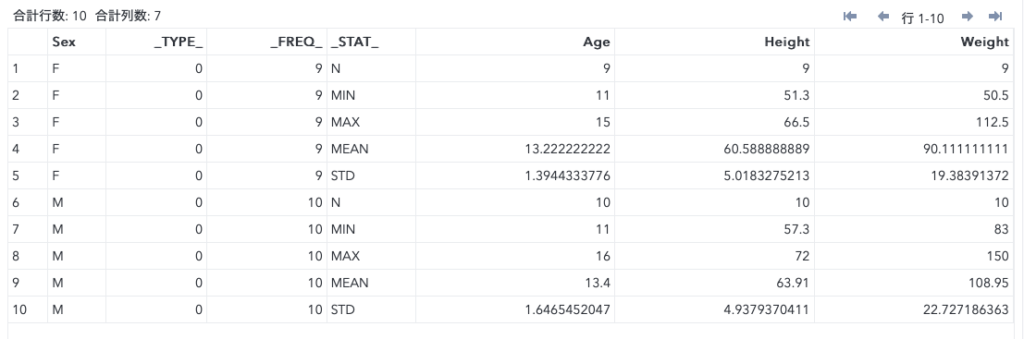
以下が出力されたclass_testです。

コメント