
概要:データセットをソートします。重複削除などでも使います。
構文
構文
PROC SORT <collating-sequence-option> <other option(s)>; BY <DESCENDING> variable-1 <<DESCENDING> variable-2 ...>; KEY variable(s); RUN;
ステートメントの説明
| ステートメント | 必須 | 解説 |
| BY | ○ | 並べ替え変数を指定。 |
| KEY | 並べ替えキーと変数を指定。 |
PROC SORTステートメントのオプション
| オプション | 必須 | 解説 | 分類 |
| ASCII | ASCIIを指定。 | ||
| DATA=SAS-data-set | 入力データセットを指定。 | ||
| DATECOPY | 作成日と変更日を変更せずにデータセットを並べ替える。 | ||
| FORCE | 強制的に冗長な並べ替えを行う。 | ||
| OVERWRITE | 置換出力データセットが作成される前に、入力データセットを削除する。 | ||
| PRESORTED | データセットがすでに並べ替えられた可能性があるかどうかを指定。 | ||
| REVERSE | 文字変数の照合シーケンスを逆順にします。 | ||
| SORTSIZE=memory-specification | 利用可能なメモリを指定します。 | ||
| TAGSORT | 一時的なディスク使用量を減らします。 | ||
| DUPOUT=SAS-data-set | 重複オブザベーションの書き込み先となる出力データセットを指定。 | Create output data sets | |
| OUT=SAS-data-set | 出力データセットを指定。 | Create output data sets | |
| UNIQUEOUT=SAS-data-set | 除外されたオブザベーションの出力データセットを指定。 | Create output data sets | |
| NODUPKEY | BY値が重複するオブザベーションを削除する。 | Eliminate duplicate observations | |
| NOUNIQUEKEY | 一意のソートキーがある出力データセットからオブザベーションを除外する。 | Eliminate unique observations | |
| NOTHREADS | スレッド化された並べ替えは実行しない。 | Override SAS system option THREADS | |
| THREADS | スレッド化された並べ替えの有効化を可能にする。 | Override SAS system option THREADS | |
| DANISH | デンマーク語を明記。 | Specify the collating sequence | |
| EBICDIC | EBCDICを指定。 | Specify the collating sequence | |
| FINNISH | フィンランド語を指定。 | Specify the collating sequence | |
| NATIONAL | カスタマイズされた順序を指定。 | Specify the collating sequence | |
| NORWEGIAN | ノルウェー語を指定。 | Specify the collating sequence | |
| POLISH | ポーランド語を指定。 | Specify the collating sequence | |
| SORTSEQ=collating-sequence | 照合シーケンスを指定。 | Specify the collating sequence | |
| SWEDISH | スウェーデン語を指定 | Specify the collating sequence | |
| EQUALS | BYグループ内の相対順序を指定。 | Specify the output order | |
| NOEQUALS | BYグループ内の相対順序を保持しない。 | Specify the output order |
例
テスト用データセットを作成
data DummyData;
input NAME $ AGE SEX $;
cards;
Aoki 10 M
Iioka 15 F
Ueki 20 M
Eto 10 F
Onozawa 10 F
;
run;
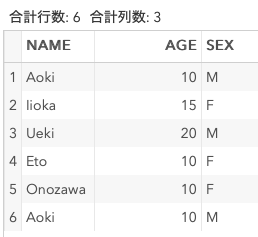
ただソートするだけ
proc sort data = DummyData out = Sorted1;
by AGE;
run;
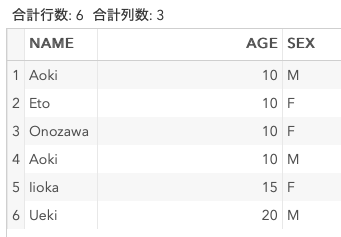
nodupkeyオプションをつけたソート
キーが重複したオブザベーションを削除します。
proc sort data = DummyData out = Sorted5 nodupkey;
by AGE;
run;

その他
nodupオプションをつけたソート
nodupオプションは公式ドキュメントに説明がありませんが、動くようなので一応メモしておきます。
proc sort data = DummyData out = Sorted2 nodup;
by AGE;
run;
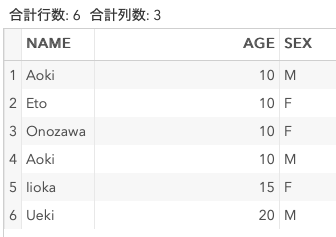
proc sort data = DummyData out = Sorted3 nodup;
by NAME;
run;
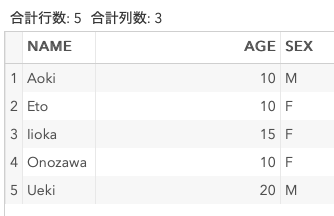
AGEをキーにしたときにもNAME=Aokiのオブザベーションが削除される予想だったが、第一変数がソートされていないと削除されないらしい。
第一変数をソートしなくてもたまたま第一変数が都合よくソートされるデータを作って試してみる。
data DummyData2;
input NAME $ AGE SEX $;
cards;
Aoki 10 M
Iioka 15 F
Aoki 10 M
Ueki 20 M
Eto 10 F
Onozawa 10 F
;
run;
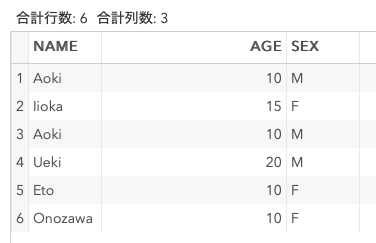
proc sort data = DummyData2 out = Sorted4 nodup;
by AGE;
run;
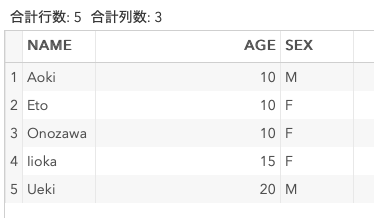
ソート状況が異なるだけでnodupオプションの挙動が異なることがわかった。
手元のマニュアルでは「すべての変数の値が重複している場合にオブザベーションを削除する」とあるが、使い方には注意が必要。

コメント