
概要
mergeしたい時、双方のデータセット内のkeyとなる変数が同じものを指す場合でも、まれにlength値が異なることがあります。新たに変数を作成してlength値を合わせることなくmergeする一例をメモしておきます。
テストデータ
data raw;
length
Subject $200
aaa $10
bbb $20;
Subject = '10000001'; aaa = 'a1'; bbb = 'b1'; output;
Subject = '10000002'; aaa = 'a2'; bbb = 'b2'; output;
Subject = '10000003'; aaa = 'a3'; bbb = 'b3'; output;
Subject = '10000004'; aaa = 'a4'; bbb = 'b4'; output;
run;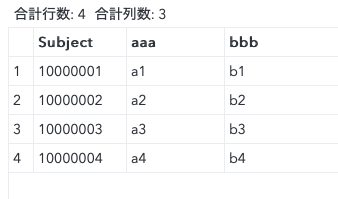
data test;
length
SUBJID $8
ccc $10
ddd $20;
SUBJID = '10000001'; ccc = 'c1'; ddd = 'd1'; output;
SUBJID = '10000002'; ccc = 'c2'; ddd = 'd2'; output;
SUBJID = '10000003'; ccc = 'c3'; ddd = 'd3'; output;
SUBJID = '10000004'; ccc = 'c4'; ddd = 'd4'; output;
run;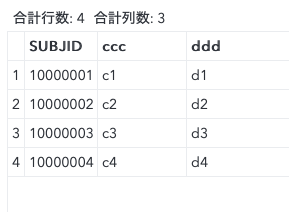
だめな例
data ret1;
merge
test( rename = ( SUBJID = Subject) )
raw
;
by Subject;
run;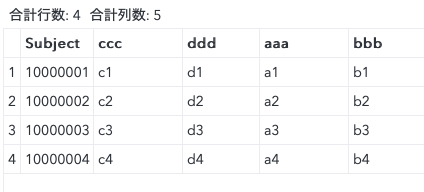
一見うまくいっているように見えます。実際にmergeされたデータセットは問題ありません。しかし、それはたまたまであってlength=$200の変数Subjectに9文字以上のデータが格納されていたら結果としてもだめなものとなります。ログでもwarningがでるのでわかりやすいです。修正が必要なコードです。

うまくいく例
じゃあどうするかというと非常に単純で、mergeの順番を変えるだけです。mergeステートメントに記載するデータセットの順番を、by変数のlength値の大きな方から記述します。それだけ。
data ret2;
merge
raw
test( rename = ( SUBJID = Subject) )
;
by Subject;
run;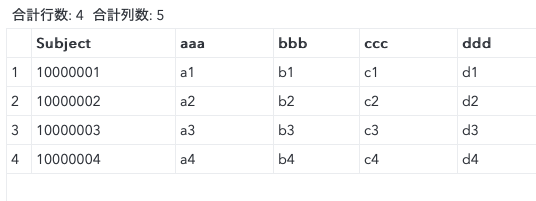

実際にこの例ではmerge後のデータセットでSUBJIDが消えてしまいますし、Subject→SUBJIDにrenameするとSUBJIDのlengthが$200になってしまうしで、後続の処理でまた工夫が必要になります。とりあえずlength値が異なっても新たに変数を準備しなくても処理できるという情報です。

コメント